

Designing with Xilinx Memory Primitives: Understanding Inference vs Instantiation
Designing with Xilinx Memory Primitives: Understanding Inference vs Instantiation
Utilizing XPMs for Enhanced Memory Management and Portability

In our last newsletter, we covered the basics of Xilinx memory primitives. Now, let’s dive into some more nuanced topics. How does choosing between synchronous and asynchronous memory access impact your design? When should you infer memory versus instantiating it?
This post explores the access characteristics of different Xilinx memory primitives and the pros and cons of each approach. Whether you’re optimizing for low latency or seeking precise control, this guide will help you make informed decisions to enhance your FPGA designs.
Synchronous vs Asynchronous Access
It is important to understand the access characteristics of different Xilinx memory primitives. This is especially important if you plan on inferring the memory primitives.
Writes to all memory primitives are always synchronous.
BlockRAMs and UltraRAMs reads synchronous, while Distributed RAM reads are asynchronous.
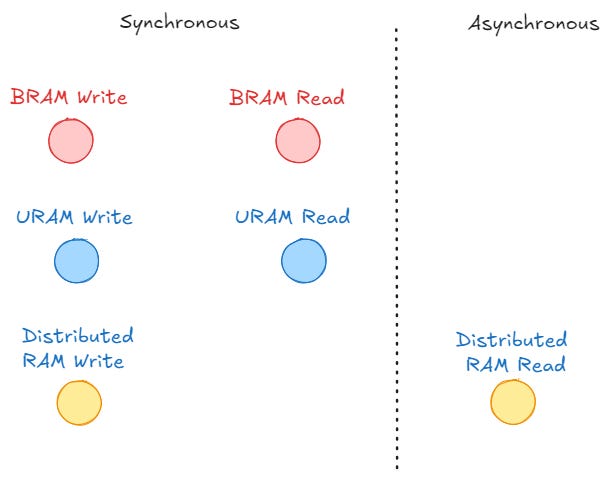
The asynchronous read feature of Distributed RAMs can be crucial for low latency applications, where the data can be read immediately without waiting for a clock edge. If synchronous read capability is desired, an additional flip-flop at the output of the Distributed RAM (LUT) is used to register the data.
Inference vs Instantiation
Instantiation involves explicitly defining the memory blocks in your HDL code using vendor-specific primitives or IP cores. This method provides precise control over the memory’s configuration and behavior.
Inference involves writing generic HDL code that the synthesis tool interprets to create the appropriate memory blocks. The tool deduces the intended memory type based on the code structure. Synthesis attributes are available to suggest the memory type intended, but the Synthesis tools have the freedom to ignore the suggestion for optimization purposes.
For critical areas of the design, I always tend to instantiate the functionality, rather than infer it. This guarantees that the synthesized netlist will be in line with what you intended.
Instantiating Memory Modules
There are two primary ways to instantiate memory modules in a Xilinx FPGA:
Generate the required memory configuration through the Vivado IP Generator tool. Vivado will generate a .xci (or the core container .xcix) file, which can then be integrated into the design during synthesis.
Use Xilinx Parameterizable Macros (XPMs). XPMs provide a standardized method to instantiate various types of memory, such as BlockRAM, UltraRAM, and distributed RAM, with customizable parameters.
Advantages of Using XPMs
Portability: XPMs facilitate easy portability across Xilinx devices. Memories generated with the Vivado IP Generator tool target a specific Xilinx part, but you can use the
upgrade_ipcommand to target a different FPGA part or a different Vivado version.Code Management and Integration: XPMs are instantiated in the HDL code, similar to any other IP module. This keeps the memory instantiation within your code, simplifying code management and version control. It also reduces makefile dependencies on other makefile targets and allows for better flexibility since configuration parameters can be managed from the HDL code rather than regenerating the IP core for specific configurations.
The main downside of XPMs (as of today) is that not all configuration options are available in the XPM instantiation template. You can achieve more complex configurations, such as very wide or deep memories with customizable pipeline stages, through the Vivado IP Generator GUI.
Here's an example of how XPMs are used to instantiate an UltraRAM.
// XPM memory instantiation
xpm_memory_spram #(
.ADDR_WIDTH_A (ADDR_WIDTH),
.MEMORY_SIZE (1024*DATA_WIDTH), // Memory size in bits
.READ_DATA_WIDTH_A (DATA_WIDTH),
.WRITE_DATA_WIDTH_A (DATA_WIDTH),
.READ_LATENCY_A (1),
.WRITE_MODE_A ("read_first")
) xpm_bram_inst (
.clka (clk),
.addra (addr),
.dina (din),
.wea (we),
.douta (dout)
);Inferring Memory Modules
Inferring code is all about portability. Inferred code can be used across multiple FPGA platforms (vendors). It is also used in instances where specific FPGA modules are ported over to an ASIC implementation at a later time.
I prefer to infer code for small and simple memories, where the overhead of generating a fresh instance through the Vivado IP Generator GUI is too time-consuming.
module inferred_uram_example (
input logic clk,
input logic [ADDR_WIDTH-1:0] addr,
input logic [DATA_WIDTH-1:0] din,
input logic we,
output logic [DATA_WIDTH-1:0] dout
);
parameter ADDR_WIDTH = 12;
parameter DATA_WIDTH = 72;
// Memory declaration with synthesis attribute for UltraRAM
(* ram_style = "ultra" *) logic [DATA_WIDTH-1:0] uram [(2**ADDR_WIDTH)-1:0];
always_ff @(posedge clk) begin
if (we) begin
uram[addr] <= din;
end
dout <= uram[addr];
end
endmoduleThe memory array uram is declared with the ram_style = "ultra" synthesis attribute, which instructs the synthesis tool to implement this memory using UltraRAM.
Takeaways
In conclusion, understanding the nuances of inferring versus instantiating memory in FPGA designs is crucial for optimizing performance and resource utilization. By leveraging the strengths of each approach, you can tailor your design to meet specific requirements, whether it’s for portability, simplicity, or advanced performance optimization. As you continue to explore and implement these techniques, you’ll be better equipped to create efficient and effective FPGA solutions that meet the demands of your projects.
💡Remember - When in doubt, always instantiate your logic.
Additional Resources
Vivado Design Suite User Guide: Synthesis (UG901) provides more information on inferring memories and XPMs.
Xilinx Vivado IDE includes language templates for inferring various types of memories in HDL and also has information about XPMs.